
Crypto and NFTs draw out a great deal of skepticism, but they may well be the best way to offer open financial products to a wide audience. My interest in financial products was sparked by Ethereum flash loans, at the same time I was reading Subprime Mortgage Credit derivatives. Before that, my knowledge of Credit Default Swaps (CDS) and Collateral Debt Obligations (CDO) was limited to what I saw in the movie The Big Short.
As far as crypto goes, I’m more into Bitcoin and not a big fan of proof of stake, but Ethereum is a bit more exciting. In December 2020, I was exploring existing projects in Decentralized Finance (DeFi) and came across NFTFi.com, a service that allows users to set up NFT-backed loans. You could provide Ether for a yield or lock your NFT to unlock liquidity. However, you had to pay the loan back; otherwise, the NFT would be liquidated, resulting in the loss of your collateral.

Given the promising potential of this niche service, I decided to build on it. The non-fungible nature of NFTs inspired me to consider offering financial derivatives on top of the loans they backed. In this blog, I will detail how I priced the risk associated with these loans using a logistic regression model trained on data from the Ethereum blockchain. Our goal was to determine the predictive power of the NFT characteristics (i.e., the NFT itself) on the likelihood of loan default (0) versus timely repayment (1). The broader Web3 project will be the subject of a more comprehensive blog post in the future.
Please note that this work was done for a proof of concept and represents just one component of a more complex Web3 product.
Goals
- Pull data from the ethereum blockchain to a Postgres database
- Get historical appraisal for our NFTs
- Make a logistic regression in Python
- Export it in a .PMML file for further use
Process
- Identify the data we’ll need and how we’ll obtain it
Alright, so we’re looking for multiple informations in order to build our regression :
-
The loan id –> simple, every loan is referenced by a unique incremented identifier
-
The NFT id and smart contract address –> It will allow us to identify our collateral and get an appraisal
-
The loan “currency”, NFTFi.com offers loans in ETH as well as in DAI. Our appraisal tool is producing results in ETH. We could set up a conversion function by pulling the historical price of the pair but that’s too much for a V1.
-
The loan value
-
The maximum repayment amount including the yield
-
The duration of the loan

NFTFi loans are publicly “stored” on the blockchain through their smart contract. Getting them will now be our next step. As of june 2023, their smart contract address is : 0x8252Df1d8b29057d1Afe3062bf5a64D503152BC8
- Pull the data from the ethereum blockchain
I considered using a third-party solution to obtain the data, but I wanted to try pulling it using Go. The Go Ethereum book has excellent documentation to get started.
We’ll also need an Ethereum node connection, for which you can use your own or use Infura’s free tier. Infura will also help us create a function that gets the latest block number on the blockchain. This will allow us to compare it to our latest update in the database and determine from which point we should sync the loans. Otherwise, we would have to parse all data from the past two years each time.
To provide data to three tables, we need three functions:
- The first one obtains the loans that started.
- The second one obtains the loans that were repaid.
- The third one obtains the loans that were liquidated.
This process is structured this way because of the Nftfi.com contract architecture. Ethereum smart contracts can store data in different ways : temp data in memory, which we can’t access anymore for these loans, storage data which we can access through a smart contract function call and through events, which are broadcasted when a specific action happens.
The loan data is not stored in storage often, except for an open loan and then it gets deleted. Our functions will go through events. Function number one could have been enough but it lacks an important information, was the loan repaid or was it liquidated ? We can’t know yet as the event is braodcasted when the loan starts. That’s why we’ll have to parse the other events and infer it from there.
//Two parameters : the starting block is the last block in our databse, the ending block is the last block in the blockchain
func GetLoanStartedEventsData(db *gorm.DB, StartingBlockNumber uint, EndingBlockNumber uint) {
//The nftfi smart contract address
contractAddress := common.HexToAddress("0x8252Df1d8b29057d1Afe3062bf5a64D503152BC8")
//Define query
query := ethereum.FilterQuery{
FromBlock: new(big.Int).SetUint64(uint64(StartingBlockNumber)),
ToBlock: new(big.Int).SetUint64(uint64(EndingBlockNumber)),
Addresses: []common.Address{
contractAddress,
},
}
//Connect to node
client, err := ethclient.Dial("YOUR_LOCAL_NODE_ADDRESS_OR_INFURA_URL")
if err != nil {
log.Fatal(err)
}
//Get events
logs, err := client.FilterLogs(context.Background(), query)
if err != nil {
log.Fatal(err)
}
//Make them readable through ABI
contractAbi, err := abi.JSON(strings.NewReader(string(NFTfiV2LoanStatus.StoreABI)))
if err != nil {
log.Fatal(err)
}
//Loop through all of them
for _, vLog := range logs {
//Topics are are a specific data category of an event, we'll talk about it later
var topics [4]common.Hash
for i := range vLog.Topics {
topics[i] = vLog.Topics[i]
}
//Check the index 0 of the topic which indicates the type of event, here we want the loan started one
if topics[0].String() != "0x42cc7f53ef7b494c5dd6f0095175f7d07b5d3d7b2a03f34389fea445ba4a3a8b" { //0x4fac0ff43299a330bce57d0579985305af580acf256a6d7977083ede81be1326
continue
}
loanOpened := struct {
//Loan related data
LoanTerms interface{}
//Block related information
LoanExtras interface{}
}{}
//Identify event struct
log.Println("event : ", event)
err = contractAbi.UnpackIntoInterface(&loanOpened, "LoanStarted", vLog.Data)
//In case of error
if err != nil || len(vLog.Topics) < 4 {
//Cut off for readibility
}
id := new(big.Int)
log.Println(loanOpened.LoanTerms)
log.Println(loanOpened.LoanExtras)
LoanTermsData := fmt.Sprintf("%v", loanOpened.LoanTerms)
LoanTerms := strings.SplitN(LoanTermsData, " ", -1)
//It's important to make a lot of checks as some loans can be faulty
if len(LoanTerms) < 1 {
log.Println("no loan data found on ethereum : empty list")
continue
}
if AlreadyRegisteredStarted(db, BigIntToInt(id.SetBytes(topics[1].Bytes()))) == true || len(vLog.Topics) < 4 {
log.Println(BigIntToInt(id.SetBytes(topics[1].Bytes())))
log.Println("Already registered")
continue
} else {
//Ethereum has no decimal mechanism, we're often working with big ints
reducer := StringToBig("1000000000000") //Allow for 6 decimals
log.Println("Added a loan with ID : ", BigIntToInt(id.SetBytes(topics[1].Bytes())))
line := NFTFiLoansStarted{
LOAN_ID: BigIntToInt(id.SetBytes(topics[1].Bytes())),
BORROWER_ADDRESS: common.HexToAddress(vLog.Topics[2].Hex()).String(),
LENDER_ADDRESS: common.HexToAddress(vLog.Topics[3].Hex()).String(),
LOAN_PRINCIPAL_AMOUNT: new(big.Int).Div(StringToBig(LoanTerms[0][1:]),reducer).Int64(),
MAXIMUM_REPAYMENT_AMOUNT: new(big.Int).Div(StringToBig(LoanTerms[1]),reducer).Int64(),
NFT_COLLATERAL_ID: LoanTerms[2],
LOAN_ERC20_DENOMINATION: LoanTerms[3],
LOAN_DURATION: LoanTerms[4],
LOAN_INTEREST_RATE_FOR_DURATION_IN_BASIS_POINTS: StringToInt(LoanTerms[5]),
LOAN_ADMIN_FEE_IN_BASIS_POINTS: StringToInt(LoanTerms[6]),
NFT_COLLATERAL_WRAPPER: LoanTerms[7],
LOAN_START_TIME: StringToInt(LoanTerms[8]),
NFT_COLLATERAL_CONTRACT: LoanTerms[9],
BLOCK_NUMBER: uint(vLog.BlockNumber),
TX_HASH: vLog.TxHash.Hex(),
}
db.Create(&line)
GetNFTMetadata(db, LoanTerms[2], LoanTerms[9])
}
}
}
Alright so here is our function, the two other functions are quite similar as we’re also listening to an event. At the same time, we also process the NFT metadata by making a call to a third party API. Which allows us to get nft specific data such as the artwork url. But we won’t need this part for our regression.
Before jumping out to the next part, here is the main function :
func main() {
db, err := gorm.Open("postgres", "host=xx.xx.xx.xxx port=xxxx user=xxxxx dbname=xxxxxx password=xxxxxxx")
if err != nil {
log.Fatal(err)
}
log.Println("Connected to database.")
defer db.Close()
db.AutoMigrate(&NFTFiLoansStarted{})
db.AutoMigrate(&NFTFiLoansLiquidatedV2{})
db.AutoMigrate(&NFTFiLoansRepaidV2{})
db.AutoMigrate(&NFTMetadata{})
//Run from scratch by batch of blocks
var substraction uint = 1500000
for i := 0; i < 1500; i++ {
log.Println("Sequence : ", i)
CurrentBlockNumber, _ := ETHLatestBlock.GetLastBlockNumber()
log.Println("Updating status from block : ", (BigIntToInt(CurrentBlockNumber) - substraction), "to : ", BigIntToInt(CurrentBlockNumber)-substraction+1000)
UpdateStatus(db, (BigIntToInt(CurrentBlockNumber) - substraction), BigIntToInt(CurrentBlockNumber)-substraction+1000)
substraction -= 1000
}
//Run from existing database
CurrentBlockNumber, _ := ETHLatestBlock.GetLastBlockNumber()
log.Println("Updating status from block : ", 1579486, "to : ", CurrentBlockNumber)
UpdateStatus(db, 1579486, BigIntToInt(CurrentBlockNumber))
CurrentBlockNumber, _ := ETHLatestBlock.GetLastBlockNumber()
LastBlockNumberUpdate := GetLowestBlockNumber(db)
log.Println("Updating status from block : ", LastBlockNumberUpdate, "to : ", CurrentBlockNumber)
UpdateStatus(db, LastBlockNumberUpdate, BigIntToInt(CurrentBlockNumber))
}
On to the appraisal !
- Appraise the NFT collaterals
We now have our loans in a database, and we know whether they’re still ongoing or have defaulted/been repaid. The next step is to obtain an appraisal, as we will need it for our regression analysis.
As we shared about our service on social media platforms such as Twitter and Discord, other projects reached out to us. One of them was Nabu. We had a call with them which lead to a key to their appraisal API. By providing the NFT ID and smart contract wrapper, we can reach out to their API. Another hidden function then saves the data in a table.
func GetNabuNFTAppraisalHistorical(NFTID string, contractAddress string, date string) (int64, int64, int64, time.Time, error) {
//log.Println("Pulling data from Nabu for : " + NFTID + " " + contractAddress)
url := "https://NABU_ENDPOINT" + contractAddress + "/" + NFTID + "/historical?before=" + date + "&offset=0"
req, _ := http.NewRequest("GET", url, nil)
req.Header.Add("accept", "application/json")
req.Header.Add("x-api-key", "YOUR_NABU_API_KEY")
res, _ := http.DefaultClient.Do(req)
defer res.Body.Close()
body, _ := ioutil.ReadAll(res.Body)
if len([]byte(body)) == 0 {
log.Fatal("No data from Nabu")
}
var data NFTAppraisal
json.Unmarshal([]byte(body), &data)
if len(data.Prices) == 0 {
return 0, 0, 0, time.Now(), errors.New("No data from nabu")
}
//log.Println(res)
return FormatETH(data.Prices[0].PriceEth), FormatETH(data.Prices[0].PriceMinEth), FormatETH(data.Prices[0].PriceMaxEth), data.Prices[0].PriceDate, nil
}
type NFTAppraisal struct {
Prices []struct {
PriceEth float64 `json:"price_eth"`
PriceMinEth float64 `json:"price_min_eth"`
PriceMaxEth float64 `json:"price_max_eth"`
PriceDate time.Time `json:"price_date"`
ModelVersion string `json:"model_version"`
} `json:"prices"`
NextOffset int `json:"next_offset"`
}
We now have a database full of appraisals.
- Set up our logistic regression
Next step will be in Python, I tried it in Go first but my results were not satisfying enough for some reasons so I switched boats. In this part we’ll use the well-known sklearn library.
Here is the data we’ll have a regression on :
- The loan principal amount
- The loan maximum repayment amount
- The interest rate
- The loan duration
- The NFT appraisal
- The loan to value ratio
Not that many parameters but it’s a good start. I also didn’t want to add such data as an appraisal spread with a MIN and MAX value because I may go for a different data provider and some don’t offer the same data. In the end we switched from Nabu to Upshot so it was the right call.

On the other side, a defaulted loans will be 0 and a repaid loan will be 1. For the sake of simplicity, the appraisal database contains loans data for ETH base loans as well as the status of the loan : Repaid/Defaulted/In progress.
Here we go :
conn = psycopg2.connect(database="xxxxxx", user = "xxxxx", password = "YOUR_PASSWORD", host = "xx.xx.xx.xxx", port = "xxxx")
print("Connected to database")
cursor = conn.cursor()
#Identify the loans which ended, meaning the ones not In Process
postgreSQL_select_Query = "SELECT * from nabu_appraisals WHERE loan_repa_id != 'In Process'"
cursor.execute(postgreSQL_select_Query)
results = cursor.fetchall()
#Print sample data as well in order to make a single test for the blog later
sampleIndex = 5133
print("SAMPLE ID", results[sampleIndex][4])
print("SAMPLE data : ", results[sampleIndex][7],",",results[sampleIndex][8],",",(float(results[sampleIndex][8])-float(results[sampleIndex][7]))/float(results[sampleIndex][7]),",",results[sampleIndex][11],",",results[sampleIndex][15],",",float(results[sampleIndex][7])/float(results[sampleIndex][15]))
print("SAMPLE status : ",results[sampleIndex][19])
#Initiate our data placeholders
tempx = []
tempy = []
for i, row in enumerate(results):
#Exclude errors
if (float(row[7]) and float(row[15])) == 0.00:
#print(i,float(row[7]),float(row[15]), "null data")
continue
#Append the data
tempx.append([float(row[7]),float(row[8]),(float(row[8])-float(row[7]))/float(row[7]),float(row[11]),float(row[15]),float(row[7])/float(row[15])])
#Append the issue of the loan
if row[19] == "Repaid":
tempy.append(1)
elif row[19] == "Defaulted":
tempy.append(0)
else:
print(i, "No loan status found")
continue
#Pivot to numpy arrays
x = np.array(tempx)
y = np.array(tempy)
#Now let's build the model,
# The `multi_class` parameter allows us to handle multi-class problems. The algorithm uses a softmax function and cross-entropy loss to predict probabilities across multiple classes
# The `random_state` parameter is used to ensure reproducibility of the results. By setting this value to 0, the algorithm will produce the same results each time it is run, given the same input data. It may be optional but I'm not sure to be frank
model = LogisticRegression(multi_class="multinomial", random_state=0)
print(model.fit(x, y))
Now let’s try it on our sample data on the loan with id 5133.
print("Prediction probabilities: ", model.predict_proba([[1900000 , 2000000 , 0.05263157894736842 , 2592000 , 359266 , 5.288560565152283]]))
print("Catégories : ",model.classes_)
print("R2", model.score(x, y))
print("Coeffs : ", model.coef_)
print("Intercept : ", model.intercept_[0])
conn.close()
We get a little over a 93% chance of having this loan reimbursed. And it was reimbursed indeed. This test was for the sake of the blog. I did test on multiple loans which were not part of the regression with satisfying results.
- Export to PMML
In order to use our regression easily, I wanted to export it to PMML format. Truth is I was hoping to reuse it in Go but importing it successfully was a nightmare. Anyway, we’ll simply need the library sklearn2pmml and a few lines of code :
#export
pipeline = PMMLPipeline([
("classifier", model)
])
#Define our data frames, we'll use panda
X = pd.DataFrame(x)
X.columns = np.array(["1","2","3","4","5","6",])
Y = pd.Series(y)
Y.name = "Issue"
pipeline.fit(X, Y)
from sklearn2pmml import sklearn2pmml
sklearn2pmml(pipeline, "MyPMMLFile.pmml", with_repr = True)
We now have a working regression and even a .pmml file. In another blog I will share about the integration with the rest of the project and making this usable through an endpoint for the users as well as for the smart contract. It was a bit more complicated than expected but it’s quite an interesting process because of the limitations.
Results
I feel like we did good for a first version of a risk assesment service. I’ll be able to improve it after all other features will be released. Keep in mind this blog is a compilation of the work I did. I faced some challenges, the smart contract changed, I had to develop functions handling new loans coming in, appraise their collateral as well as pull other data for some other parts of the project. Set up all the code on a server to provide the tables with new loans data.
You can actually access the loans data on a secondary page of the website, no yield displayed though. I will share more about the whole project in another blog.
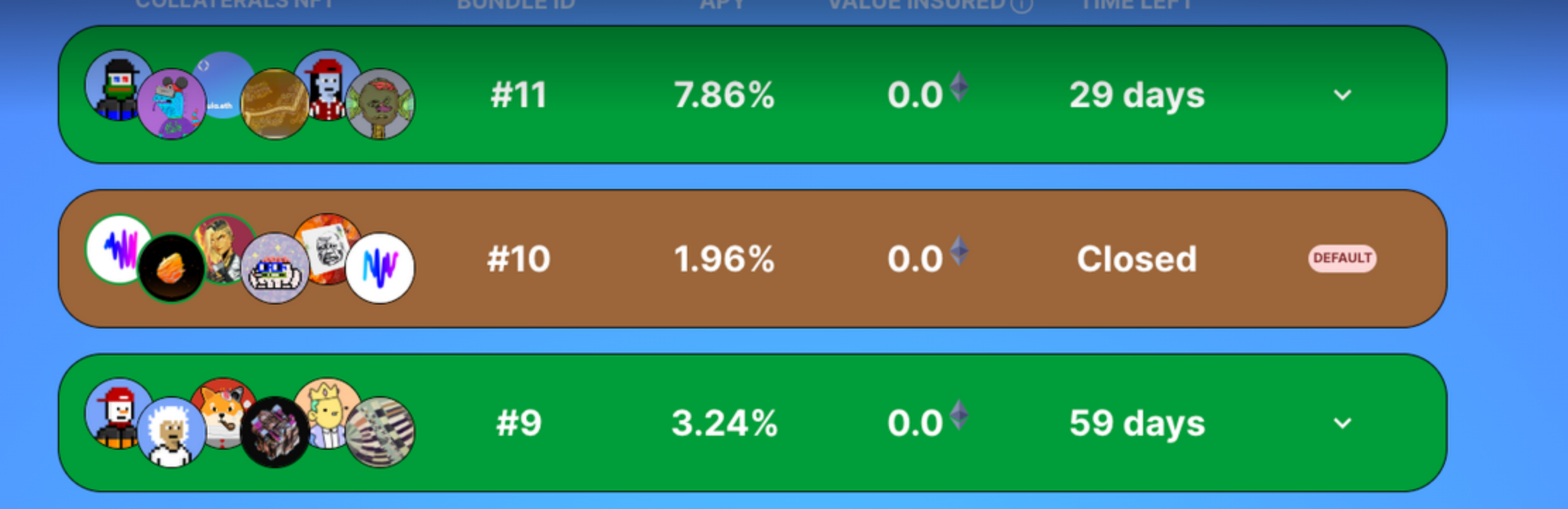
I also feel like the probabilities we got for the loans are quite good and fit well with the dynamic of the new loans coming in. Felt good working on it, I feel like the next step for me is pushing beyond linear and logistic regression. I’ll probably explore the Go machine learning library Gorgonia this summer.
Review
-
Documentation I feel like this part of the project has extended ramifications which are not well documented enough. Depending on a Infura key, a third party smart contract, an ubuntu server, Go code, Python code, Node JS code for the front end and our Postgres database is a lot to manage when you come back to it a few months later. I feel like I should learn how to document code with such dependencies.
-
Golang regression not working As stated in the blog, I tried it out in Go and struggled a bit with the results, I feel like I should try it out again at some point. Importing the pmml file in Go was neither working as expected.
-
Obvious limitations to the model Of course it’s a first version but it’s still highly limitated. It has quite a few parameters, does not account for ETH price evolution, the industry is quite young. The appraisal is not quite dynamic, I’ve had the same appraisal for days on some NFTs with active trading. The regression does not account for NFT collections as well, which can have huge impacts on the price of a NFT.
-
Such markets are also under threat of market manipulations. The NFTFi.com service is quite young and I feel like the lenders and borrowers are quite a close-knit community, increasing the social pressure on users liquidating loans. We can also face other manipulations as it’s quite a complex ecosystem which goes beyong NFTFi.com and even beyond the NFT market.

- Last critique would be about using Python instead of Go. The Python regression works well but it’s not easily deployable to the cloud or simply not easy to deploy as a webservice. In another blog I will share about I overcame that and the issues it brought.
As always, thanks for reading and feel free to reach out.